NOTA
====
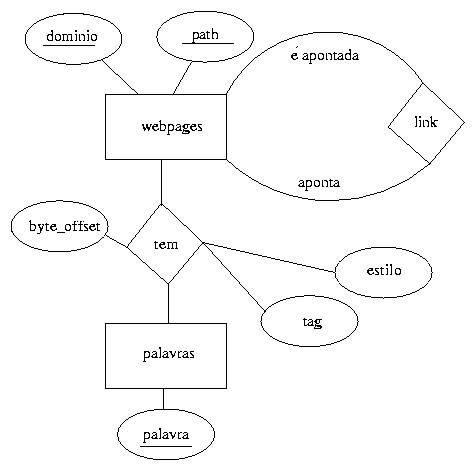
* 'byte_offset' dá a posição da palavra no ficheiro (serve para
distinguir as várias ocorrências da mesma palavra).
* 'tag' poderá ter o valor ('notag', '<h1>', '<h2>', '<title>').
* 'estilo' poderá ter o valor ('normal', 'bold', 'itálico').
* ignorei 'protocolo' porque assumi que é sempre 'http'.
Conceptualmente a utilização de um código único é desnecessário visto que a url (dominio+pathname) pode ser utilizada como chave. No entanto, tendo em vista a conversão para o modelo relacional, é extremamente vantajoso um número inteiro único para chave. A justificação para esta escolha reside no facto de se poupar muito espaço em disco, uma vez que esta chave irá ser um atributo da relação 'Tem' assim que se converter para o modelo relacional. Reparem que a relação 'Tem' será uma associação de muitos para muitos e terá uma dimensão muito grande (nota: a mesma justificação é válida para o conjunto de entidades 'Palavras'. Isto é, poderíamos ter 'PalavraID' e 'Palavra' como atributos).
Webpages( pageID, dominio, path ) /* (dominio + path) é único */
------
Palavras( palavraID, palavra ) /* palavra é único */
---------
Links( page1_ID, page2_ID) /* page1_ID aponta para page2_ID */
-------- --------
Tem( pageID, palavraID, byte_offset, estilo, tag )
------ --------- -----------
CREATE TABLE Webpages (
pageID INTEGER PRIMARY KEY,
dominio VARCHAR(100) NOT NULL,
path VARCHAR(100) NOT NULL,
UNIQUE (dominio,path)
);
CREATE TABLE Palavras (
palavraID INTEGER PRIMARY KEY,
palavra VARCHAR(100) UNIQUE NOT NULL
);
CREATE TABLE Links (
page1_ID INTEGER REFERENCES Webpages,
page2_ID INTEGER REFERENCES Webpages,
PRIMARY KEY (page1_ID, page2_ID)
);
CREATE TABLE Tem (
pageID INTEGER REFERENCES Webpages,
palavraID INTEGER REFERENCES Palavras,
byte_offset INTEGER NOT NULL,
estilo DominioEstilo NOT NULL,
tag DominioTag NOT NULL,
PRIMARY KEY (pageID, palavraID, byte_offset)
);
CREATE DOMINIO DominioEstilo CHAR(10)
CHECK (VALUE IN ('normal', 'bold', 'italic'));
CREATE DOMINIO DominioTag CHAR(10)
CHECK (VALUE IN ('notag', '<title>', '<h1>', '<h2>'));
Também aceito como certo, respostas que não tenham 'pageID' e 'palavraID'. Ou seja, aceito como certo o seguinte:
Webpages( dominio, path )
------- ----
Palavras( palavra )
-------
Links( dominio1, path1, dominio2, path 2 )
-------- ----- -------- ------
Tem( dominio, path, palavra, byte_offset, estilo, tag )
------- ---- -------
CREATE TABLE Webpages (
dominio VARCHAR(100),
path VARCHAR(100),
PRIMARY KEY (dominio,path)
);
CREATE TABLE Palavras (
palavra VARCHAR(100) PRIMARY KEY
);
CREATE TABLE Links (
dominio1 VARCHAR(100),
path1 VARCHAR(100),
dominio2 VARCHAR(100),
path2 VARCHAR(100),
PRIMARY KEY (dominio1, path1, dominio2, path2),
FOREIGN KEY (dominio1,path1) REFERENCES Webpages,
FOREIGN KEY (dominio2,path2) REFERENCES Webpages
);
CREATE TABLE Tem (
dominio VARCHAR(100),
path VARCHAR(100),
palavra VARCHAR(100),
byte_offset INTEGER NOT NULL,
estilo DominioEstilo NOT NULL,
tag DominioTag NOT NULL,
PRIMARY KEY (dominio, path, palavra, byte_offset),
FOREIGN KEY (dominio, path) REFERENCES Webpages,
FOREIGN KEY (palavra) REFERENCES Palavras
);
CREATE DOMINIO DominioEstilo CHAR(10)
CHECK (VALUE IN ('normal', 'bold', 'italic'));
CREATE DOMINIO DominioTag CHAR(10)
CHECK (VALUE IN ('notag', '<title>', '<h1>', '<h2>'));
Vou assumir o modelo relacional que inclui IDs para webpages e palavras. Para resolver estas questões dá jeito criar 2 views, 'TemView' e 'LinksView', de modo a simplificar as queries em SQL. Estas views seriam o equivalente às tabelas Tem e View caso optássemos pelo modelo relacional sem IDs.
CREATE VIEW TemView( dominio, path, palavra, byte_offset, estilo, tag ) AS
SELECT dominio, path, palavra, byte_offset, estilo, tag
FROM Webpages W, Tem T, Palavras P
WHERE W.pageID = T.pageID
AND T.palavraID = P.palavraID;
CREATE VIEW LinksView( dominio1, path1, dominio2, path2 ) AS
SELECT W1.dominio, W1.path, W2.dominio, W2.path
FROM Links L, Webpages W1, Webpages W2
WHERE L.page1_ID = W1.pageID
AND L.page2_ID = W2.pageID;
Vamos às queries em SQL:
a)
SELECT dominio, path
FROM TemView
WHERE palavra = 'Jardel'
AND ((tag = '<h1>') OR (tag = '<h2>'));
b)
SELECT dominio2, path2
FROM LinksView
WHERE dominio2 LIKE '%.pt'
AND (dominio1,path1) <> (dominio2,path2)
GROUP BY dominio2, path2
HAVING COUNT(*) >= ALL (
SELECT COUNT(*)
FROM LinksView
WHERE dominio2 LIKE '%.pt'
AND (dominio1,path1) <> (dominio2,path2)
GROUP BY dominio2, path2
);
c) Interpretação possível: <title> é uma palavra
(apesar de também ser um tag)
CREATE ASSERTION MaxUmTitle AS
NOT EXISTS (
SELECT dominio, path
FROM TemView
WHERE palavra = '<title>'
GROUP BY dominio, path
HAVING COUNT(*) > 1
);
Nota: esta pergunta poderia ter várias interpretações.
Também aceitaria como certo quem tivesse interpretado a
pergunta como "Quais as página que não têm mais do
que uma palavra dentro do tag <title>"
Não. Os verdadeiros search engines apenas necessitam de oferecer consultas. Desse modo, podem ser optimizados utilizando estruturas de dados próprias, não necessitando do "overhead" imposto pelos SGBDs (que permitem updates, deletes, inserts).
-
Sim, O resultado em SQL poderá ter estúdios repetidos. Em Álgebra Relacional isso nunca poderá acontecer porque uma relação é um conjunto, e por definição, um conjunto não tem elementos repetidos. Para o output ser sempre o mesmo, teríamos de fazer SELECT DISTINCT na query em SQL.
-
Não está nada mal feito.
- Sim.
numero --> curso, nota, maisque6, copiou nota --> maisque6 'maisque6' é um atributo derivado de nota. É redundante, e pode-se eliminar. Existe também dependências funcionais "parciais". Exemplo: copiou --> nota /* se copiou == TRUE */ copiou --> maisque6 /* se copiou == TRUE */ No entanto, se copiou for FALSE, nada se poderá concluir. Reparem também que o facto da nota ser zero não implica que o aluno tenha copiado. -
Alunos( numero, curso, nota ) ------ Copiou( numero ) /* lista de alunos que copiaram */ ------ Também aceito como certo se tivessem posto: Alunos( numero, curso, nota, copiou ) ------ visto que assim também está em BCNF.